Control de procesos básico
Procesos y estados
Un proceso o tarea es todo aquel programa en ejecución. Los programas se guardan en el disco mientras que los procesos se almacenan en memoria (RAM). Cuando lanzas un programa, a este se le asigna un numero de proceso, si este a su vez llama a otros programas (hijos) a estos también se les asigna un numero de proceso. Cuando el ‘padre’ muere también deben morir todos sus hijos para garantizar la consistencia del sistema.
Estos procesos tienen asignados una serie de identificadores llamados UID (ID del usuario propietario) y GID (ID del grupo al que pertenece). Para ver estos parámetros usamos el comando ‘ps’ aunque si queremos una salida más ‘gráfica’ podemos usar el comando ‘top’ el cual nos saca en una lista todos los procesos activos y se muestra de tal manera que el primer proceso es que más recursos consume y el último proceso es el que menos consume.
Monitorización y control de procesos
A los procesos que se encuentran activos podemos monitorizarlos o enviarles determinadas señales para que realicen determinadas acciones como : ps, pstree, pgrep, kill, pkill, top, etc.
PS
El comando ps nos informa del estado de los procesos, lee la información directamente del fichero /proc. Las principales opciones son:
Columna
|
Resultado
|
p
| Muestra el ID |
P
| Muestra el ID del proceso padre |
U
| Muestra el usuario propietario |
T
| Muestra el tiempo de uso acumulado por la CPU |
NI
| (Nice) Muestra la prioridad en un intervalo de entre -19 a 19. |
S
| Muestra el estado del proceso, corriendo, dormido, parado... |
PSTREE
Muestra los procesos en forma de árbol, si agregas la opción -A y -G se muestra de una forma más gráfica.
KILL
El comando kill se usa principalmente para matar o terminar procesos y todos sus hijos, aunque también se usa para enviar señales a los procesos y estos realicen diferentes acciones según la señal enviada. Se usa con la sintaxis ‘kill -opciones PID’. La opción por defecto es -15, la cual mata o termina un proceso.
Opción
|
Resultado
|
-1
| Manda una señal de pausa |
-18
| Manda una señal de continuar para un proceso en pausa |
-19
| Manda una señal que detiene el proceso |
-2
| Manda una señal para terminar un proceso |
-9
| Manda una señal que mata el proceso incondicionalmente |
Si queremos conocer todas las opciones posibles de kill tendremos que ejecutar el comando ‘kill -l’.
KILLALL
El comando killall es muy similar a kill con la diferencia de que en vez de indicar un PID indicaremos el nombre del proceso por lo cual si tenemos varios procesos con el mismo nombre y matamos uno de ellos, mataremos a todos los demás procesos con el mismo nombre.
NICE
Con nice podemos cambiar la prioridad de los distintos procesos, esta prioridad va desde el -19 (alta prioridad) hasta el +19 (baja prioridad). Los cambios negativos solo los puede realizar el superusuario o root.
RENICE
Así como nice permite modificar su prioridad antes de la ejecución del proceso, renice permite modificar la prioridad mientras el proceso esta ejecutándose, sin necesidad de tener que detener el proceso.
NOHUB -&
Usamos nohub o & para ejecutar un proceso en segundo plano y dejar libre la consola de mandos. Si mandamos de forma manual un proceso a segundo plano tenemos el inconveniente de que la terminal se convierte en el PPID (proceso padre) por lo que si cerramos la terminal o cerramos sesión, estos procesos morirán sin importar que fueran. Si queremos ejecutar un programa en segundo plano seguiremos esta sintaxis ‘./programa.sh -&’.
TOP
Top se usa para listar de una forma más gráfica los procesos que se encuentran ejecución, es útil porque muestra varios parámetros entre ellos el uso de recursos del sistema. Se ordenan de forma que el programa que usa más recursos se encuentra el primero, y el programa que usa menos recursos se encuentra el último.
Jobs
Con el comando jobs podemos ver todos los procesos que se están ejecutando en segundo plano. los procesos en segundo plano pueden al foreground con el comando ‘fg numero de proceso’. Si el proceso se encuentra en foreground y queremos enviarlo a background usaremos el comando ‘bg numero de proceso’. Para matar un proceso podemos usar la combinación de teclas CTRL+C o CTRL+Z. Tambien es posible matarlos con kill %1 y el numero del proceso.
Hilos de ejecución
Los hilos son usados en programación lo que hace que al ejecutar un programa, este hace uso de diferentes recursos del sistema. Se puede monitorizar con el comando ‘ps -T -p numero de proceso’.
Gestor de arranque GRUB
El gestor de arranque permite seleccionar que sistema operativo queremos arrancar. Linux usa el gestor de arranque GRUB (Grand Unified Bootloader) el cual accede al directorio /boot donde carga el kernel y ejecuta el proceso ‘init’. Al contrario que Windows que usa el gestor de arranque MBR (Master Boot Record) y se trata de una carga encadenada en la que el MBR indica donde se encuentra el primer sector de la partición con el sistema.
Cuando se añade un nuevo kernel al sistema, GRUB los añade a las opciones de arranque del sistema y modifica los ficheros de configuración.
Si queremos realizar algún cambio en la configuración de GRUB, lo haremos en el fichero ‘/etc/default/grub’ y los cambios de las imagens de arranque se hacen en el fichero ‘/etc/grub.d’. Y siempre despues de cada cambio deberemos actualizar la configuración con el comando ‘update-grub2’.
Arranque y parada del sistema
En los sistemas Linux, para iniciar el sistema se ejecuta el programa init, el cual va ejecutando una serie de tareas de forma ordenada, las cuales son:
- Comprueba los sistemas de ficheros
- Monta los sistemas de ficheros permanentes
- Activa la swap del sistema
- Activa los demonios o servicios del sistema
- Activa la red
- Inicia los servicios de red del sistema
- Limpia los sistemas de ficheros temporales
- Habilita el login a los usuarios
Podemos cambiar el nivel de ejecución actual de la máquina con el comando ‘init numero’ donde el numero varia de 1 a 6 según lo que queramos hacer, por ejemplo ‘init 0’ apaga el sistema, ‘init 6’ reinicia el sistema, etc. El fichero donde se encuentra la configuración de los distintos niveles del sistema se encuentra en /etc/rcN.d, donde N es el numero de nivel. Cuando el sistema arranca primero ejecuta los scripts que comienzan por S y cuando ha terminado de ejecutar estos scripts, ejecuta los scripts que comienzan por K.
Servicios del sistema
Los servicios del sistemas son aplicaciones que se ejecutan en segundo plano y sirven para ofrecernos ciertos servicios como son la red, consola, etc. Para ver que servicios se arrancan en cada nivel de ejecución realizaremos el siguiente comando:
> chkconfig –list
En otros sistemas más modernos como Linux 7 se usa el comando ‘systemctl’, como por ejemplo: ‘systemctl status sshd’
El kernel
El kernel de un sistema operativo se encarga de dar vida al hardware del equipo, es responsable de asegurar que todos los programas y procesos puedan tener acceso simultaneamente a los recursos necesarios para ejecutarse. Es el cerebro de un sistema operativo encargado de coordina el acceso al hardware y los datos entre los diferentes componentes del sistema. La capa que sigue al kernel es la capa software donde se ejecutan las aplicaciones de usuario.
Para poder saber la versión del kernel hacemos el comando ‘uname -r’
Administración y gestión de usuarios
Los usuarios se encuentran registrados en el fichero /etc/passwd y las contraseñas de estos se encuentran en el fichero /etc/shadow. Para desactivar el fichero shadow realizamos el comando ‘pwunconv’ y para actualizar y crear el fichero shadow usamos el comando ‘pwconv’.
Permisos especiales sobre ficheros
Hay algunos permisos que pueden ser ejecutados por usuarios que no sean root en ciertas circunstancias. Hay que tener cuidado con estos permisos porque podrían dañar la seguridad del sistema.
Estos permisos especiales se activan con chmod y suman un dígito más al principio. Estos son los permisos especiales con sus respectivos dígitos:
- Activar setuid → 4(100)
- Activar setgid → 2(010)
- Activar sticky bit → 1(001)
- Activar setuid y sticky bit → 5(101)
Setuid
El bit setuid permite que ciertos usuarios puedan acceder a ficheros o directorios de otro usuario. Esto e sutil para fichero que tienen que ser ejecutados o visualizados por los usuarios pero cuyo propietario es root, como es el caso del fichero ‘passwd’.
Setgid
Este permiso especial es muy similar al setuid pero con la diferencia de que en vez de afectar a usuarios afecta a grupos, por lo que un usuario aunque no pertenezca al grupo capaz de ejecutar un fichero, puede ejecutarlo sin pertenecer al mismo. Si se aplica a un directorio y tu con el permiso setgid creas un fichero dentro de dicho directorio, el fichero pertenecerá al grupo del fichero padre, no a ti.
Sticky bit
El permiso especial sticky bit protege los ficheros dentro de un directorio dejando que solo puedan ser modificados por el propietario o por root, así evitamos que un usuario elimine fichero de un directorio publico donde todos los usuarios tienen permisos de escritura.
Gestión de discos y sistemas de ficheros
Los sistemas Linux organizan los datos en forma de árbol de directorios con ficheros dispuestos de forma jerárquica. El sistema identifica cada dispositivo externo o partición con un directorio dentro de su árbol de directorios ‘/dev/sda1’.
- -s → Identifica si el disco es sata o scsi
- -h → Identifica si el disco duro es de tipo IDE
- -a → Identifica el primer disco, b seria el segundo y así continuamente
- -1 → Identifica la partición dentro del disco
Con la herramienta fdisk podemos realizar la gestión del particionado de discos de una forma sencilla, el único inconvenientes es que no dispone de herramienta gráfica. Después de realizar la partición hay que crear un directorio y montar la partición en dicho directorio con el comando ‘mount /dev/sda1 /datos’.
Sistemas RAID
Los Raid (Redundant Array of Independent) es un conjunto de discos que actúan como un solo sistema de almacenamiento, los cuales son capaces de soportar el fallo de unos de los discos sin perder información debido a su sistemas de redundancias.
Para trabajar con Raid usamos los comandos mdadm en Ubuntu o lvm en RedHat.
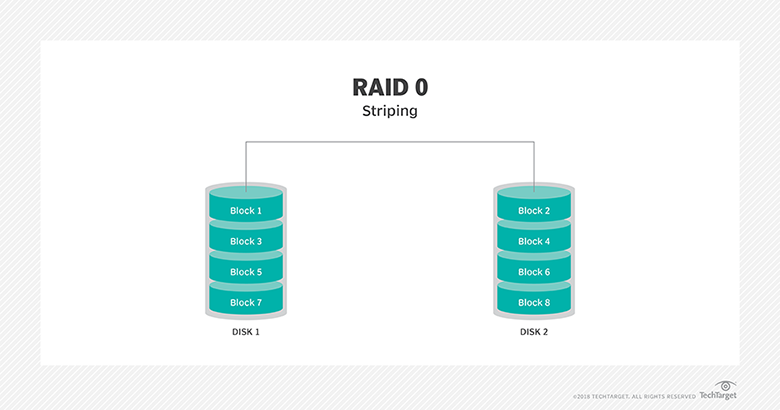
- El raid 0 no tiene redundancias, los discos se ponen uno detrás del otro haciendo que para el usuario haya un gran volumen en vez de varios discos, si falla un disco el sistema de ficheros se verá dañado.
- El raid 1 supone una duplicidad de los datos, soporta el fallo de un disco y es capaz de regenerarlo. La duplicidad en los datos supone que se va a ocupar el doble de espacio.
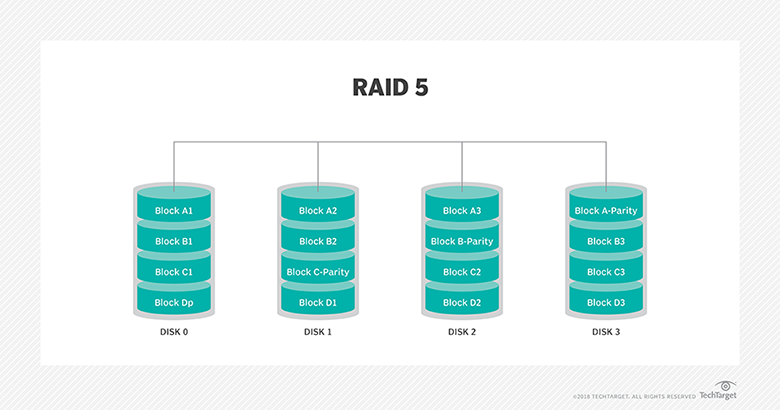
- El raid 5 se compone de varios discos en los que se genera una redundancia de datos pero sin duplicar, cada bloque de datos en vez de encontrarse en un solo disco, se distribuye por los discos reservando unos de ellos para guardar exclusivamente información de paridad. Si uno de ellos falla, los datos se pueden reconstruir gracias a la paridad.
Administración y configuración
Para agregar una interfaz de red realizamos el siguiente comando:
>ifconfig <interfaz> <IP> netmask <mascara_de_red> up
Rutas y puerta de enlace
Se usa para conectar el equipo a otra red diferente, para ello realizamos el siguiente comando:
>route add -net 0/0 gw <IP puerta de enlace> <Interfaz>
Valores de red permanentes
Para almacenar los cambios en la configuración de red de forma permanente sin borrarse a cada reinicio del sistema deberemos introducir los datos en los fichero ‘/etc/network/interfaces’ y ‘/etc/sysconfig/network-scripts’. También podemos modificar el nombre del equipo en el fichero ‘/etc/hostname’.
Resolución de nombres
Para configurar la resolución de nombre se usa el fichero ‘/etc/hosts’. Para establecer la configuración mediante DNS deberemos entrar en el fichero ‘/etc/resolv.conf’ e indicaremos los nombres de los namservers.
Reiniciar el servicio de red
En Ubuntu usaremos el comando ‘/etc/init.d/networking force-reload’ para reiniciar el servicio de red.
Comando
|
Resultado
|
ifconfig
|
Información de la conexión y adaptadores
|
route
|
Muestra la tabla de enrutamientos
|
iptables
|
Muestra y configura el cortafuegos
|
service
|
Administrar los servicios del sistema
|
adduser
|
Agregar usuario
|
userdel
|
Borrar usuario
|
usermod
|
Modificar valores del usuario
|
passwd
|
Cambiar la contraseña del usuario
|
addgroup
|
Permite dar de alta un usuario dentro de un grupo
|
su
|
Cambiar de usuario
|
id
|
Muestra el usuario que se está utilizando
|
groups
|
Grupos a los que pertenece el asuario
|
groupadd
|
Dar de alta un grupo
|
groupdel
|
Borrar un grupo
|
mdadm
|
Crear un raid
|
fdisk
|
Particionado de discos
|
chage
|
Establecer periodos de contraseñas
|
pwconv
|
Crear y actualizar el fichero /etc/shadow
|
pwunconv
|
Desactivar el fichero /etc/shadow
|
uname -r
|
Versión del kernel
|
chkconfig –-list
|
Gestionar servicios del sistema
|
init 0-6
|
Cambiar el nivel de ejecución del sistema
|
fg proceso
|
Llevar un proceso a primer plano
|
bg proceso
|
Llevar un proceso a segundo plano
|
jobs
|
Lista los trabajos en segundo plano dentro de la shell
|
top
|
Ver procesos activos en forma ‘gráfica’
|
nohub - &
|
Poner un proceso en segundo plano
|
nice
|
Cambiar la prioridad al iniciar un proceso
|
renice
|
Cambiar la prioridad con el proceso en ejecución
|
kill PID
|
Matar un proceso
|
killall nombre
|
Matar un proceso con nombre
|
pstree -AGu
|
Listar los procesos en forma de árbol
|
mkfs.ext3
|
Formatear particiones
|
mount
|
Montar discos en punto de anclaje
|